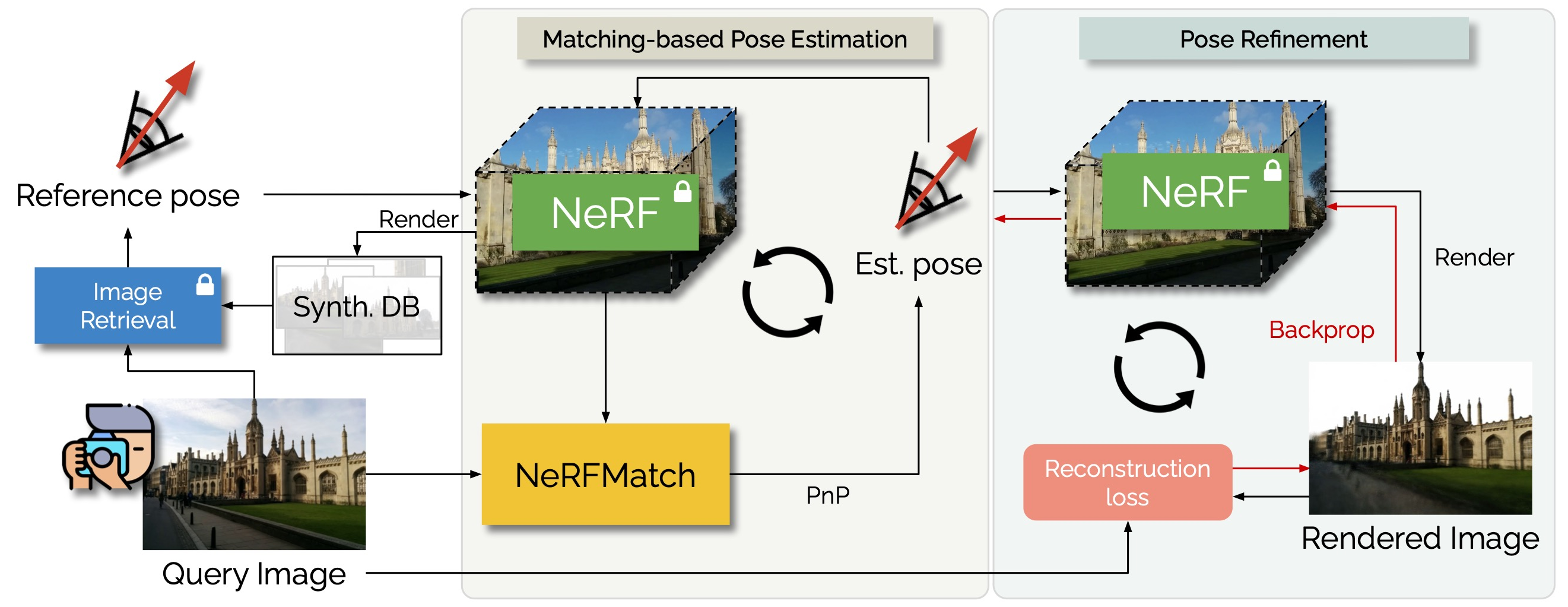
In this work, we propose the use of Neural Radiance Fields (NeRF) as a scene representation for visual localization. Recently, NeRF has been employed to enhance pose regression and scene coordinate regression models by augmenting the training database, providing auxiliary supervision through rendered images, or serving as an iterative refinement module. We extend its recognized advantages – its ability to provide a compact scene representation with realistic appearances and accurate geometry – by exploring the potential of NeRF’s internal features in establishing precise 2D-3D matches for localization. To this end, we conduct a comprehensive examination of NeRF’s implicit knowledge, acquired through view synthesis, for matching under various conditions. This includes exploring different matching network architectures, extracting encoder features at multiple layers, and varying training configurations. Significantly, we introduce NeRFMatch, an advanced 2D-3D matching function that capitalizes on the internal knowledge of NeRF learned via view synthesis. Our evaluation of NeRFMatch on standard localization benchmarks, within a structure-based pipeline, achieves competitive results for localization performance on Cambridge Landmarks.
@article{zhou2024nerfmatch,
title={The NeRFect match: Exploring NeRF features for visual localization},
author={Zhou, Qunjie and Maximov, Maxim and Litany, Or and Leal-Taix{\'e}, Laura},
journal={European Conference on Computer Vision},
year={2024}
}